在当今数据驱动的世界中,数据预处理已成为机器学习和数据科学中不可或缺的关键环节。它不仅影响模型的性能,还直接关系到分析结果的准确性和可靠性。
数据预处理的重要性体现在多个方面。原始数据通常存在各种问题,如缺失值、异常值、不一致的格式和噪声等。若不进行适当处理,这些问题会严重影响机器学习模型的训练效果。例如,缺失值可能导致模型无法学习完整的特征关系,而异常值可能扭曲模型的决策边界。
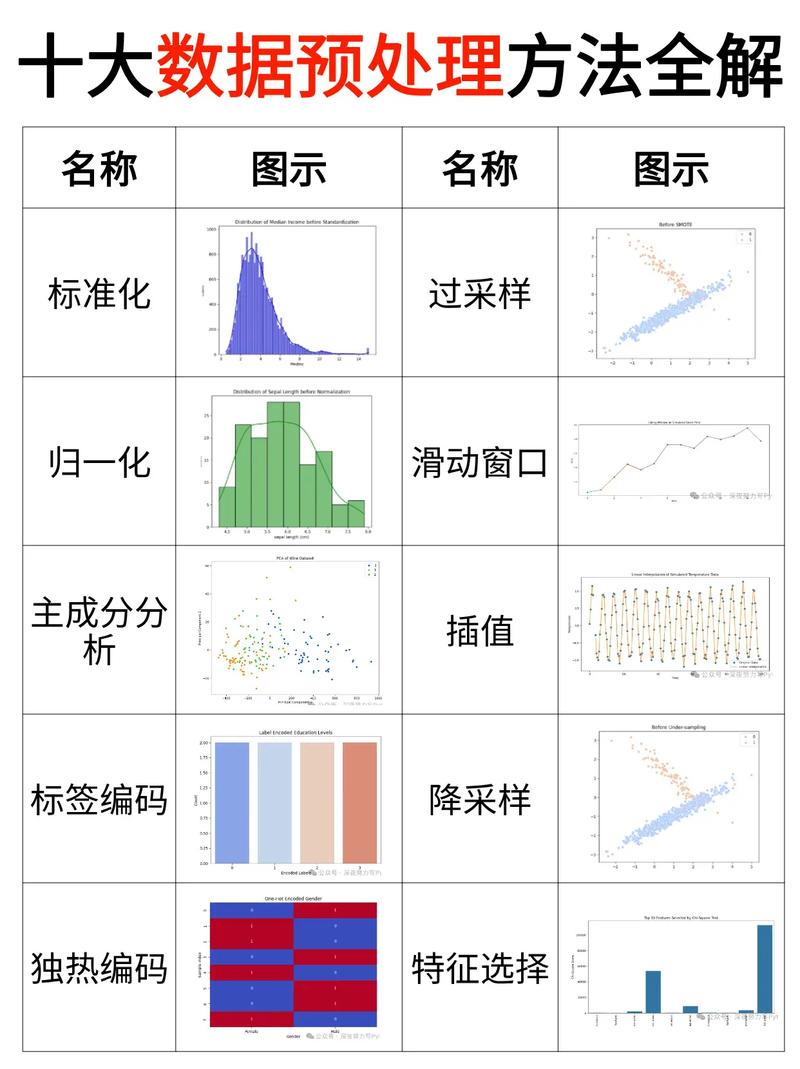
数据预处理的主要步骤包括数据清洗、数据集成、数据变换和数据规约。数据清洗涉及处理缺失值(通过删除或填充)、识别并处理异常值;数据集成将来自不同源的数据合并成一致的数据集;数据变换包括标准化、归一化和特征编码等操作,使数据更适合模型处理;数据规约则通过降维或采样方法减少数据量,提高计算效率。
值得注意的是,不同的问题场景需要采用不同的预处理策略。在监督学习中,标签数据的质量直接影响模型性能;在非监督学习中,数据的内在结构和分布是预处理的重点。随着深度学习的发展,针对图像、文本等非结构化数据的专用预处理技术也日益成熟。
实践证明,精心设计的数据预处理流程往往能显著提升模型性能。在许多实际应用中,数据预处理所花费的时间甚至超过模型训练本身,这充分说明了其在机器学习工作流中的核心地位。因此,任何希望在数据科学领域取得成功的从业者,都必须掌握扎实的数据预处理知识和技能。